I principi FAIR sono linee guida per rendere Reperibili (Findable), Accessibili (Accessible), Interoperabili (Interoperable) e Riutilizzabili (Reusable) tutti i risultati della ricerca come, ad esempio, i dati, i software e i protocolli. Tali princìpi sono stati formulati e pubblicati formalmente nel 2016 su Nature Scientific Data.
REPERIBILI
Innanzitutto i dati dovrebbero essere facili da trovare sia dagli umani che dalle macchine (machine-readable) e questo può essere fatto attraverso identificati attraverso metadati appropriati (informazioni che descrivono i dati ) e attraverso identificativi univoci e persistenti (URL stabili cui corrisponderà per sempre quella risorsa, DOI, handles, ecc.).
Inoltre, i dati andrebbero conservati per almeno 10 anni in un archivio che offra garanzie, in molteplici copie e in ambienti sicuri anche durante la ricerca, non solo al termine.
ACCESSIBILI
I dati e i metadati devono essere accessibili, il che non significa “aperti”, ma significa sapere come arrivare ai dati e come poterli eventualmente visionare e scaricare attraverso un protocollo aperto, libero e implementabile ovunque. Possono essere previste procedure di autenticazione e autorizzazione e/o accordi di riservatezza.
Il principio guida da seguire è “il più aperto possibile, chiuso il necessario” a seconda delle specifiche esigenze, ad esempio ai fini della protezione di dati sensibili o della proprietà intellettuale.
I metadati giocano anche in questo caso un ruolo fondamentale, anche per segnalare la necessità di particolari protocolli di trasmissione (diversi da http://) o la presenza di API – Application programming Interface.
Idealmente, per essere Accessibili, i dati dovrebbero essere salvati in formati non proprietari, non compressi, non criptati e con standard documentati.
INTEROPERABILI
I dati devono essere descritti utilizzando standard rilevanti per la comunità di riferimento. Uno strumento prezioso in questo senso è il registro FAIR sharing, una risorsa curata e informativa sugli standard dei dati e dei metadati, correlati alle banche dati e alle politiche sui dati.
RIUTILIZZABILI
L'obiettivo finale dei principi FAIR è quello di ottimizzare il riutilizzo dei dati. Per raggiungere questo obiettivo, i metadati e i dati dovrebbero essere ben descritti in modo da poter essere replicati e/o combinati in contesti diversi e dovrebbero avere una licenza d'uso dei dati chiara e accessibile, come ad esempio le Creative Commons (qui il License Selector Tool utile per la scelta della licenza).
Ogni lettera dell'acronimo "FAIR" si riferisce a un elenco di principi, per un totale di 15 principi. L'elenco completo e ulteriori informazioni sono disponibili alla pagina web di GOFAIR ad essi dedicata.
Verificare se i propri dati della ricerca sono stati gestiti secondo i principi FAIR può essere un lavoro difficile e laborioso. Per aiutare in questo compito, negli anni sono stati definiti diversi strumenti e diverse metriche. EUDAT, in particolare, ha elaborato una lista di controllo di autovalutazione, che può facilmente essere tradotta in una serie di domande:
Findable / Rintracciabili
- E' stato assegnato un identificatore persistente (es. DOI, Handle, URL) al dataset?
- Il dataset è stato descritto con metadati dettagliati, informativi e accurati?
- I metadati sono registrati in un catalogo online o in un data repository che sia indicizzato nei motori di ricerca?
- Nei i metadati è incluso anche l'identificatore persistente assegnato al dataset?
Accessible / Accessibili
- Seguendo l'identificatore persistente si accede correttamente ai dati o ai metadati associati?
- Il protocollo di recupero dei dati e dei metadati rispetta un linguaggio standardizzato e riconosciuto come ad esempio quello della pagine web (HTTP)?
- I metadati saranno sempre pubblici, visibili e indicizzabili anche se i dati non sono in open access o non sono più disponibili?
Interoperable / Interoperabili
- I dati sono disponibili in formati aperti o almeno in formati documentati e diffusi?
- I metadati seguono schemi standard riconosciuti e condivisi?
- Sono stati utilizzati quanto più possibile vocabolari controllati o ontologie?
- Sono resi disponibili link o relazioni con altre risorse rilevanti per la comprensione dei dati come pubblicazioni o rapporti tecnici o applicazioni software?
Re-usable / Riutilizzabili
- I dati sono accurati, completi e descritti in modo che siano facilmente comprensibili e riproducibili?
- Al dataset è attribuita una licenza che ne specifica le modalità di riutilizzo?
- Dai metadati e dalla documentazione allegata è possibile evincere in maniera chiara le responsabilità scientifiche e le finalità dei dati prodotti?
- I dati e i metadati rispettano gli standard e i protocolli di qualità del dominio di ricerca di riferimento?
Oltre a questa lista di autovalutazione, sono disponibili anche alcuni strumenti online per la valutazione automatica del rispetto dei principi FAIR dei propri dataset. Nessuno di questi è completamente esaustivo, ma servono a dare delle indicazioni di massima sui propri dataset.
F-UJI è un servizio web che permette di valutare la "FAIRness" dei propri dati in maniera automatica se si possiede un PID (DOI o URL) associato al dataset che si vuole valutare. E' basato su metriche sviluppate dal progetto FAIRsFAIR.
FAIR self assessment tool strumento di autovalutazione della "FAIRness" dei propri dati a cura dell’Australian Research Data Commons.
FAIR Enough anche questo è un servizio web grazie al quale inserendo il DOI, la URL o l'handle di una risorsa online (=il proprio dataset o altro prodotto della ricerca) si ottiene una valutazione sulla conformità ai principi FAIR. E' un servizio sviluppato dalla Maastricht University.
Dati FAIR NON significa dati APERTI.
La "A" dell'acronimo "FAIR" indica che i dati devono essere in qualche modo accessibili, ma non per forza aperti a tutti.
Ricorda che i dati possono essere riservati ma essere comunque gestiti secondo i principi FAIR. Il principio guida da seguire è “il più aperto possibile, chiuso quanto necessario” a seconda delle specifiche esigenze. Per esigenze etiche, di privacy o di protezione della proprietà intellettuale alcuni dati potrebbero dover rimanere chiusi.
Per saperne di più:
What is the difference between “FAIR data” and “Open data” if there is one?
Three camps, one destination: the intersections of research data management, FAIR and Open
Pensa a come la ricerca e l'innovazione potrebbero avanzare più velocemente grazie alla maggiore riproducibilità e trasparenza consentite da dati FAIR/Aperti e pensa alle persone che potrebbero trarre vantaggio dai tuoi dati. Il primo in assoluto a beneficiare dei dati FAIR sei tu!
"Come scienziato, dovresti trattare i tuoi dati come una lettera d'amore al tuo sé futuro" (Lambert Heller, Biblioteca nazionale tedesca di scienza e tecnologia - Nature Index 360o Feb 2019)
Fonte immagine: Sara Jones, DCC, University of Glasgow, Open Science Days 2015, 21st & 23rd April, Prague & Brno

Gli standard per la metadatazione dei dati variano da disciplina a disciplina. Alcune risorse che possono essere utili per trovare gli standard per il tuo specifico campo di ricerca sono:
- FAIRSharing, una risorsa accurata, istruttiva e ricca di informazioni sugli standard di dati e metadati, correlati ai database e alle policy dei dati.
- Dublin Core, uno schema di metadati generico
- DCC metadata directory, è una raccolta di standard di metadati specifici per disciplina
- Data Documentation Initiative o DDI, offre standard internazionali per dati qualitativi e osservativi
- RDA alliance ha un github repository di standard di metadati specifici per soggetto
In alcuni campi dell'ingegneria, della tecnologia e del design, gli standard per i dati e i metadati sono ancora in evoluzione. È utile verificare con la propria comunità di ricerca lo sviluppo e la co-creazione di questi standard.
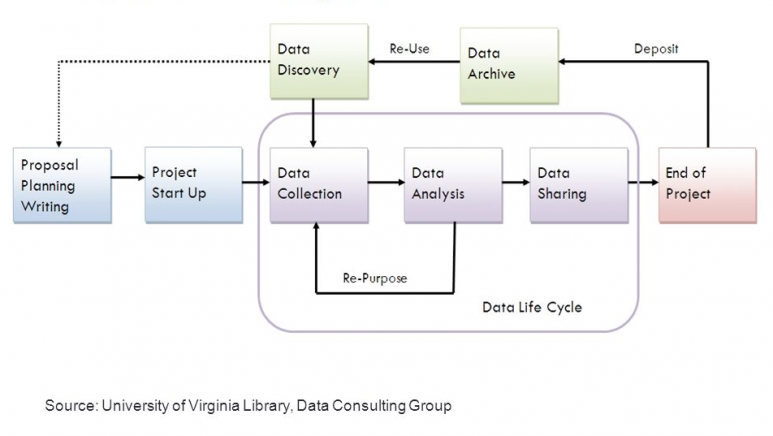
Gestire i dati della ricerca significa curarli e organizzarli in modo consapevole e responsabile durante tutto il ciclo della ricerca.
Le strategie di gestione dei dati vanno quindi elaborate sin dalle fasi di iniziali di progettazione della ricerca, coinvolgendo poi tutte le fasi operative di produzione, raccolta e analisi dati, per concludersi con la loro preservazione (archiviazione a lungo termine) e possibilmente con la condivisione.
Ciascuna fase prevede però di prendere in considerazione aspetti diversi e ben precisi della gestione dei dati.
FASE DI PIANIFICAZIONE: in questa fase del progetto occorrerà innanzitutto identificare la tipologia e la natura dei dati che si andrà a generare ex-novo o a riutilizzare e le possibili problematiche annesse (privacy, proprietà intellettuale, principi etici). Si dovrà anche pensare all’identificazione dei metadati da associare ai dati per una loro corretta descrizione e interpretazione, all’organizzazione dei dati in cartelle e alle regole di nomenclatura dei file. Il Data Management Plan dovrebbe cominciare a prendere vita in questa fase.
FASE DI RACCOLTA, GENERAZIONE ED ELABORAZIONE DATI: durante questi stadi del progetto si dovrà pensare alla conservazione dei dati in storage adeguati e alle strategie di backup. Si dovrà inoltre tenere traccia del “versioning” dei files e definire le modalità di condivisione dei dati con gli eventuali partner del progetto, prevedendo, qualora necessario, sistemi di accesso con autenticazione e autorizzazione. Sarà anche fondamentale decidere l'organizzazione dei file e delle cartelle in modo gerarchico, seguendo una nomenclatura coerente e prediligendo formati per i dati possibilmente aperti e standard.
FASE FINALE DEL PROGETTO: con l'approssimarsi della fine del progetto, occorrerà valutare quali dati depositare per la conservazione a lungo termine, scegliendo il repository più adatto e affidabile e in linea con i principi FAIR. La scelta del repository dovrebbe ricadere su quelli certificati e che garantiscano standard di sicurezza e controllo. Altro aspetto da considerare è l’associazione di una licenza ai dati che ne specifichi le modalità di riutilizzo, laddove possibile.
Per maggiori informazioni vedere le sezioni sottostanti "Che cos'è un repository e come posso sceglierne uno?" e "Criteri per selezionare i dati da conservare a lungo termine".
Le diverse discipline di ricerca possono avere output di ricerca molto diversi tra di loro e potrebbe essere necessario considerare vari elementi per decidere cosa selezionare e preservare. Non tutto va preservato e archiviato.
Di seguito alcune linee guida generali che si applicano alla maggior parte delle discipline di ricerca. Per la tua disciplina, verifica le migliori pratiche seguite dalla tua comunità di ricerca e/o consulta l'esperto di dominio per la Scienza Aperta del Politecnico (mauro.paschetta@polito.it).
Depositare sicuramente:
- Set di dati originali, codice software originale, dati grezzi ottenuti dall'analisi di campioni fisici, dati osservazionali che non possono essere rigenerati.
- Set di dati non originali e non facilmente disponibili o reperibili online, di cui si hai il permesso di condividere.
- Per i dati delle scienze sociali, includere descrizioni di studi, libri di codici e statistiche riassuntive.
Eventualmente depositare:
- Versioni intermedie di analisi o codice se potenzialmente utili ad altri o se sono state utilizzate in pubblicazioni o tesi.
Non è necessario depositare:
- Versioni di codice incomplete, non funzionali o intermedie che sarebbero di utilità marginale per altri.
- File di output dalle analisi se il set di dati e il codice utilizzati per generare l'output sono depositati e se è abbastanza facile rigenerare l'output dai file depositati.
- Set di dati conservati e accessibili tramite altre istituzioni o organizzazioni.
- Grafici o tabelle creati dai dati originali che potrebbero essere facilmente rigenerati.
Non depositare:
- Qualsiasi dato che contenga informazioni personali che identifichino soggetti umani o dati che potrebbero violare contratti legali.
Eccezioni:
- I file di output delle analisi possono essere depositati se richiedono molto tempo per rigenerarsi o se non sono eccessivamente grandi o non possono essere facilmente ricreati dal set di dati e dal codice depositati.
Il repository, nel contesto dei dati/output della ricerca, è un ambiente digitale che consente di preservare i dati della ricerca e altri output digitali a lungo termine. Essenzialmente dovrebbe offrire le seguenti funzionalità:
- Memorizza i dati in modo sicuro
- Assicura che i dati siano reperibili
- Descrive i dati in modo appropriato (metadati)
- Aggiunge informazioni sulla licenza
È possibile depositare i dati in un repository generico (ad es. Zenodo, Harvard Dataverse, Dryad) o in un repository specifico per soggetto (ad es. IoChem-BD per la chimica computazionale e scienza dei materiali, OpenEI per l'energetica, ORNL DAAC per la biogeochimica).
Cerchi un repository specifico per la tua disciplina? Puoi provare a cercare su www.re3data.org, un registro globale online di archivi di dati di ricerca di tutte le discipline accademiche.Guarda una dimostrazione della ricerca di repository di dati utilizzando la directory re3data.
Come buona pratica e in linea con la Policy d'Ateneo sulla gestione dei dati della ricerca, dopo il deposito nel repository da te scelto, ti invitiamo ad archiviare i metadati dei tuoi dataset nell’archivio istituzionale PORTO@IRIS, nella tipologia “9. FAIR Data Collection”.
OpenAIRE fornisce una guida dettagliata ai costi che ti darà un'indicazione su tempo, impegno e budget necessari per le attività relative al RDM che vanno dall'archiviazione dei dati, dalla pulizia dei dati, dai costi delle licenze software all'analisi dei dati, fino all'archiviazione in un repository.
Ricorda che questi costi possono essere messi a budget nelle tue proposte di finanziamento.
I software sono ormai una componente fondamentale dell’attività di ricerca. I ricercatori utilizzano il software per attività di ricerca, sviluppano il proprio software come parte dei risultati della ricerca e il software stesso può essere oggetto di studio.
Per una buona pratica scientifica, il software di ricerca, proprio come i dati, dovrebbe aderire ai principi FAIR per consentirne la piena riproducibilità e riutilizzo. Data però la sua natura evolutiva, la sua architettura composita e la sua codificazione in linguaggio macchina richiede alcune pratiche di archiviazione e manutenzione particolari.
La pubblicazione di software di ricerca open source è una pratica consolidata nella scienza su piattaforme come GitHub e GitLab.
Crescenti iniziative di comunità come software carpentries aiutano a formare i ricercatori, che non hanno un background specifico nello sviluppo o nella programmazione di software, per stabilire flussi di lavoro che li aiutino a gestire, monitorare, preservare e, se possibile, condividere o pubblicare software di ricerca utilizzando strumenti di automazione delle attività e sistemi di controllo delle versioni come Git.
Per ulteriori informazioni su come rendere FAIR il software: